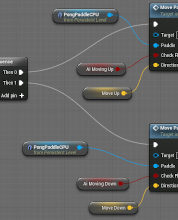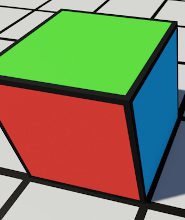
Tutorial: How To Make a Cube Roll On A Grid in Unreal Engine 4
In this tutorial, I will show how to make a cube roll from side-to-side on a grid. This project took me around 3 days to complete, though much of that was wrapping my head around basic things in UE4. Some of the areas explored here include setting up