Creating a 3D Game Engine (Part 23)
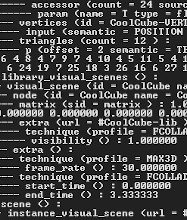
While I implemented frustum culling a little while ago, I never actually coded a proper bounding volume. For the bounding test I was using a sphere, but I just set the radius to some hard-coded value. This was fine when I just had a bunch of similar sized cubes on screen, however it broke apart once I started getting varied models imported. This