Creating a 3D Game Engine (Part 19)
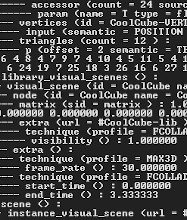
While getting models loaded was pretty exciting, I ended up dealing with major load times on the demo. Granted, my XML parsing code is probably slow as all hell, but I don’t think COLLADA is really designed for real-time engine use. With simple plane and cube shapes the